from pyspark.sql.functions import col
import altair as alt
import pandas as pd
from matplotlib import pyplot as plt
get_ipython().run_line_magic('matplotlib', 'inline')
csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_movie_tags.csv")
tag_csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_tag.csv")
csv.show()
+---+--------+------+ | id|movie_id|tag_id| +---+--------+------+ | 1| 9909| 1| | 2| 9909| 2| | 3| 9909| 3| | 4| 9909| 4| | 5| 9910| 5| | 6| 9910| 6| | 7| 9910| 7| | 8| 9910| 8| | 9| 9910| 9| | 10| 9910| 10| | 11| 9911| 12| | 12| 9911| 2| | 13| 9911| 1| | 14| 9911| 13| | 15| 9910| 11| | 16| 9911| 14| | 17| 9911| 15| | 18| 9911| 5| | 19| 9910| 16| | 20| 9910| 17| +---+--------+------+ only showing top 20 rows
csv.printSchema()
root |-- id: string (nullable = true) |-- movie_id: string (nullable = true) |-- tag_id: string (nullable = true)
from pyspark.sql.functions import col, desc, lit
csv = csv.withColumn("tag_id",col("tag_id").cast("Integer")).withColumn("count", lit(1))
csv.printSchema()
root |-- id: string (nullable = true) |-- movie_id: string (nullable = true) |-- tag_id: integer (nullable = true) |-- count: integer (nullable = false)
tag_rdd = csv.select('tag_id').join(tag_csv, csv.tag_id == tag_csv.id, "inner")
tag_rdd.show()
+------+---+--------------------+--------------------+--------+--------+ |tag_id| id| create| update| name|describe| +------+---+--------------------+--------------------+--------+--------+ | 1| 1|7/5/2020 09:36:51...|26/8/2020 00:52:5...| 本土| null| | 2| 2|7/5/2020 09:36:51...|26/8/2020 00:52:5...| 正妹| null| | 3| 3|7/5/2020 09:36:51...|26/8/2020 00:52:1...|第一人稱| null| | 4| 4|7/5/2020 09:36:52...|27/8/2020 03:30:2...| 口交| null| | 5| 5|7/5/2020 09:37:38...|25/8/2020 04:36:3...| 制服| null| | 6| 6|7/5/2020 09:37:39...|26/8/2020 00:52:5...|獨家推薦| null| | 7| 7|7/5/2020 09:37:39...|26/8/2020 00:52:3...| 痴女| null| | 8| 8|7/5/2020 09:37:39...|6/8/2020 11:08:56...| 苗條| null| | 9| 9|7/5/2020 09:37:40...|6/8/2020 11:08:56...| 業餘| null| | 10| 10|7/5/2020 09:37:40...|25/5/2020 01:39:4...| 辣妹| null| | 12| 12|7/5/2020 09:37:41...|26/8/2020 00:52:0...| 自慰| null| | 2| 2|7/5/2020 09:36:51...|26/8/2020 00:52:5...| 正妹| null| | 1| 1|7/5/2020 09:36:51...|26/8/2020 00:52:5...| 本土| null| | 13| 13|7/5/2020 09:37:42...|10/8/2020 04:29:2...| 水手服| null| | 11| 11|7/5/2020 09:37:40...|28/7/2020 23:48:3...|角色扮演| null| | 14| 14|7/5/2020 09:37:42...|17/8/2020 01:12:0...| 學生| null| | 15| 15|7/5/2020 09:37:43...|25/8/2020 04:36:5...| COSPLAY| null| | 5| 5|7/5/2020 09:37:38...|25/8/2020 04:36:3...| 制服| null| | 16| 16|7/5/2020 09:37:42...|8/5/2020 04:00:48...| 女學生| null| | 17| 17|7/5/2020 09:37:44...|6/8/2020 11:08:56...|體內射精| null| +------+---+--------------------+--------------------+--------+--------+ only showing top 20 rows
tag_rdd.first()
tr = tag_rdd.select('name')
tag_count_rdd = tr.rdd.map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y)
tag_count_rdd.take(10)
[(Row(name='本土'), 787), (Row(name='業餘'), 760), (Row(name='辣妹'), 76), (Row(name='角色扮演'), 173), (Row(name='COSPLAY'), 365), (Row(name='配信専用'), 669), (Row(name='無毛'), 46), (Row(name='230ORETD'), 7), (Row(name='眼鏡'), 22), (Row(name='流出'), 340)]
tp = tag_count_rdd.sortBy(lambda a: a[1],ascending=False).toDF().toPandas()
tp.head()
| _1 | _2 | |
|---|---|---|
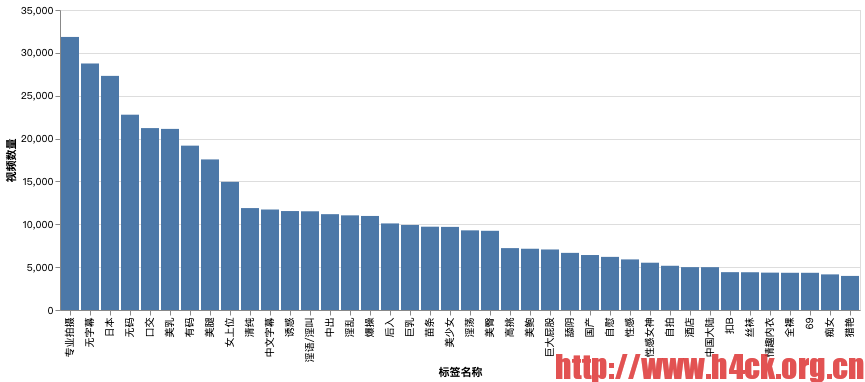
| 0 | (专业拍摄,) | 31857 |
| 1 | (无字幕,) | 28760 |
| 2 | (日本,) | 27314 |
| 3 | (无码,) | 22786 |
| 4 | (口交,) | 21224 |
# 视频标签数量展示
alt.Chart(tp[:40]).mark_bar().encode(
x=alt.X('_1', title='标签名称', sort='-y'),
y=alt.Y('_2', title='视频数量')
)
tag_count_rdd.saveAsTextFile('hdfs://localhost:9000/mapreduce/movie_tag_data')
# model信息
movie_model_csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_movie_pron_model.csv")
model_csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_pornmodel.csv")
movie_model_csv.show(10)
+---+--------+------------+ | id|movie_id|pornmodel_id| +---+--------+------------+ | 1| 47610| 1| | 2| 47611| 2| | 3| 47612| 2| | 4| 47613| 2| | 5| 47614| 2| | 6| 47615| 2| | 7| 47616| 2| | 8| 47617| 2| | 9| 47618| 2| | 10| 47619| 2| +---+--------+------------+ only showing top 10 rows
model_csv.show(10)
+---+--------------------+--------------------+-----------------+--------+--------------+--------------------------+--------+ | id| create| update| name|describe| name_en| name_jp|third_pk| +---+--------------------+--------------------+-----------------+--------+--------------+--------------------------+--------+ | 1|26/5/2020 05:47:1...|28/5/2020 18:06:4...| 菅野松雪| null| Kanno Sayuki| 菅野さゆき、かんの さゆき| CP_455| | 2|26/5/2020 05:47:1...|27/8/2020 03:30:2...| 素人| null| null| null| CP_1442| | 3|26/5/2020 05:47:4...|25/8/2020 04:36:5...| 网红| null| null| null| CP_1464| | 4|26/5/2020 05:49:4...|20/8/2020 03:15:3...| 模特| null| null| null| CP_1465| | 5|26/5/2020 05:53:3...|27/8/2020 03:30:2...| 水果派a龟| null| null| null| CP_5243| | 6|26/5/2020 05:54:0...|29/5/2020 06:38:5...| 主播| null| null| null| CP_1496| | 7|26/5/2020 05:54:1...|20/8/2020 03:14:4...| 动画人物| null| null| null| CP_1918| | 8|26/5/2020 05:54:3...|28/5/2020 14:29:5...| 古濑玲| null|Hinamori Ayumi| 古瀬リカ| CP_1943| | 9|26/5/2020 05:54:3...|24/8/2020 10:15:1...|上原亚衣/上原亜衣| null| Ai Uehara| 上原亜衣、うえはら あい| CP_847| | 10|26/5/2020 05:54:3...|29/5/2020 00:33:5...|相内史织/相内诗织| null| Aiuchi Shiori|相内しおり、あいうちしおり| CP_1065| +---+--------------------+--------------------+-----------------+--------+--------------+--------------------------+--------+ only showing top 10 rows
movie_model_rdd = movie_model_csv.select('movie_id','pornmodel_id').join(model_csv, movie_model_csv.pornmodel_id == model_csv.id, "inner")
movie_model_rdd.select('movie_id','pornmodel_id', 'name').show(10)
+--------+------------+--------+ |movie_id|pornmodel_id| name| +--------+------------+--------+ | 47610| 1|菅野松雪| | 47611| 2| 素人| | 47612| 2| 素人| | 47613| 2| 素人| | 47614| 2| 素人| | 47615| 2| 素人| | 47616| 2| 素人| | 47617| 2| 素人| | 47618| 2| 素人| | 47619| 2| 素人| +--------+------------+--------+ only showing top 10 rows
movie_mode_rdd = movie_model_rdd.select('name')
model_count_rdd = movie_mode_rdd.rdd.map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y)
model_count_rdd.take(10)
[(Row(name='菅野松雪'), 18), (Row(name='素人'), 25824), (Row(name='网红'), 156), (Row(name='模特'), 161), (Row(name='水果派a龟'), 48), (Row(name='主播'), 262), (Row(name='动画人物'), 917), (Row(name='古濑玲'), 14), (Row(name='上原亚衣/上原亜衣'), 63), (Row(name='相内史织/相内诗织'), 7)]
mtp = model_count_rdd.sortBy(lambda a: a[1],ascending=False).toDF().toPandas()
mtp.head()
| _1 | _2 | |
|---|---|---|
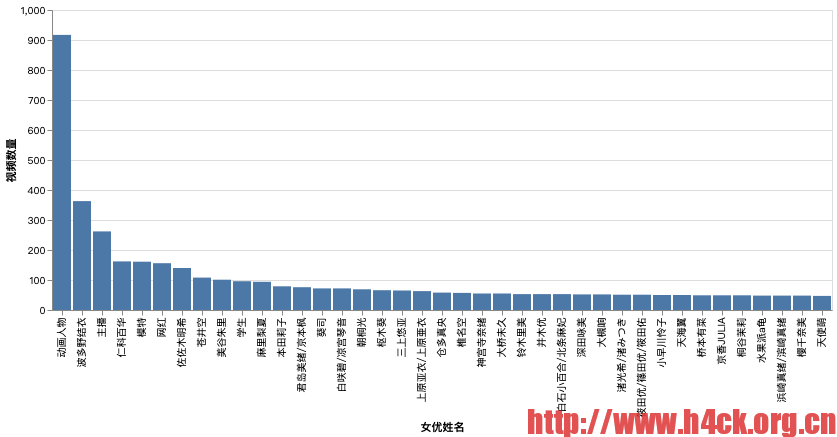
| 0 | (素人,) | 25824 |
| 1 | (动画人物,) | 917 |
| 2 | (波多野结衣,) | 363 |
| 3 | (主播,) | 262 |
| 4 | (仁科百华,) | 162 |
# 女优作品数量展示
alt.Chart(mtp[1:40]).mark_bar().encode(
x=alt.X('_1', title='女优姓名', sort='-y'),
y=alt.Y('_2', title='视频数量')
)
github:https://github.com/obaby/Porn-Data-Anaylize